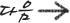Character Functions
1. CONCAT : 문자열 결합
CONCAT('Hello', 'World') → 'HelloWorld'
'Hello' || 'World' → 'HelloWorld' (문자열 겹합과 동일)
2. SUBSTR : 문자열 추출
SUBSTR('HelloWorld', 6) → 'World'
- 왼쪽에서 6번째부터 끝까지 추출
SUBSTR('HelloWorld', 6, 3) → 'Wor'
- 왼쪽에서 6번째 부터 3글자 추출
SUBSTR('HelloWorld', -4, 2) → 'or'
- 인덱스가 음수인 경우 오른쪽에서 부터 4칸 계산
3. LENGTH : 문자열의 길이 리턴
LENGTH('HelloWorld') → 10
4. INSTR : 문자의 index 값을 리턴
INSTR('HelloWorld', 'W') → 6
INSTR('HelloHello', 'H') → 1 (왼쪽에서 첫번째 문자 검색함)
INSTR('HelloHello', 'H', 1, 2) → 6 (첫번째 인자는 검색 시작 위치를, 두번째 인자 값은 반복 횟수를 나타냄)
5.
~PAD : 문자열 패딩
↑ 채울 위치 (L / R)
LPAD('abc', 6, '*') → 'abc***' (전체 6글자에서 남는 위치는 '*'로 채운다)
RPAD('abc', 6, '*') → '***abc' (전체 6글자에서 남는 위치는 '*'로 채운다)
6. REPLACE : 문자 대체
REPLACE('011-546-2456', '-', '.') → '011.546.2456
7. ~TRIM : Garbage한 문자 제거
LTRIM('aaababaaa', 'a') → 'babaaa'
RTRIM('aaababaaa', 'a') →
'aaabab
'
TRUM('a' from 'aaababaaa') → 'bab'
TRIM(' bab ') → 'bab' (지우고 싶은 문자가 공백인 경우 인자를 명시 하지 않으면 됨)
select employee_id, concat(first_name, last_name) NAME, job_id, length(last_name) , instr(last_name, 'a') "Contains 'a'?"
from employees
where substr(job_id, 4) = 'REP';
| EMPLOYEE_ID |
NAME |
JOB_ID |
LENGTH(LAST_NAME) |
Contains 'a'? |
| 174 |
EllenAbel |
SA_REP |
4 |
0 |
| 176 |
JonathonTaylor |
SA_REP |
6 |
2 |
| 178 |
KimberelyGrant |
SA_REP |
5 |
3 |
| 202 |
PatFay |
MK_REP |
3 |
2 |
Number Functions
1. ROUND : 소수점 이하 2자리 까지 표현 한다. 소수점 3째 자리에서 반올림
ROUND(45.926, 2) → 45.93
ROUND(45.926, 1) → 45.9
ROUND(45.926, 0) or ROUND(45.926) → 46 (Default 값이 0이므로 0은 생략 할 수 있다.)
ROUND(45.926, -1) → 50 (음수 인자는 반올림을 할 자릿수를 나타낸다. -1은 정수 첫번째 자리를 나타낸다.)
ROUND(45.926, -2) → 0 (반올림 할 숫자가 없기 때문에 0을 리턴)
2. TRUNC : 원하는 부분 밑으로 소수점 이하를 자른다. 인자값 만큼 소수점 이하 자리를 유지 시킨다.
TRUNC(45.926, 2) → 45.92
TRUNC(45.926, 1) → 45.9
TRUNC(45.926, 0) or TRUNC(45.926) → 45
TRUNC(45.926, -1) → 40
TRUNC(45.926, -2) → 0
* Default Date 형식 바꾸기
alter session set nls_date_format = 'YYYY-MM-DD'
session 대신 system을 하면 default 값을 변경할 수 있지만 권한을 가지고 있는 dba만 변경 가능
날짜 Data에 대한 연산은 덧셈이나 뺄셈만 가능
(곱셉이나 나눗셈은 안됨)
date - date = 상수
date + date (x) 실행 안됨
sysdate + 1/24 = 한시간 뒤 시간
sysdate + 5/1440 = 5분 뒤 시간
select last_name, (sysdate-hire_date)/7 as WEEks
from employees
where department_id = 90;
| LAST_NAME |
WEEKS |
| King |
1175.08442 |
| Kochhar |
1056.94156 |
| De Haan |
884.084418 |
Data Type Conversion
select salary * '12' (문자를 곱해도 에러 없이 실행이 잘됨. 문자 12가 숫자로 변환된다.)
from employees
암시적인 데이타 변환이 성능에 안좋게 영향을 미칠 수 있다.
TO_NUMBER TO_CHAR
NUMBER
↔ CHARACTER
↔ DATE
To_CHAR To_DATE
select to_char(sysdate, 'yyyy-mm-dd')
from dual;
왼쪽에 있는 날짜 데이터를 포맷에 맞추어 출력
| TO_CHAR(SYSDATE,'YYYY-MM-DD') |
| 2009-12-23 |
select to_char(sysdate, 'DD-Month, YYYY')
from dual;
select to_char(sysdate, 'DD-Month-YYYY', 'NLS_DATE_LANGUAGE=
korean') (원하는 언어로 출력 가능)
from dual; french
| TO_CHAR(SYSDATE,'DD-MONTH-YYYY','NLS_DATE_ |
| 23-12월-2009 |
* NLS : National Language Support
Sample Format Elements of Valid Date Formats
WW - 연중 몇주차
W - 월 몇주차
DDD - 연중 몇일째
DD - 월중 몇일째
D - 주중 몇일째
select to_char(sysdate, 'WW W DDD DD D')
from dual;
| TO_CHAR(SYSDATE,'WWWDDDDDD') |
| 51 4 357 23 4 |
select to_char(to_date('1981-10-01', 'YYYY-MM-DD'), 'DAY')
(to_date 안의 함수 안에서 날짜 형식을 지정해 주어야 인식이 된다.)
from dual;
| TO_CHAR(TO_DATE('1981-10-01 |
| THURSDAY |
7일의 표시
dd : 07
fmdd : 7
ddsp : seven
ddspth : seventh (서수형 표시)
select to_char(sysdate, 'yyyy')
from dual;
오늘 날짜에서 연도만 추출
to_char 함수는 실제로 날짜를 추출 하는 역할을 많이 한다. 동시에 문자 데이터로 변환
정수 부분이 표시할 공간이 부족할 경우 오버 플로우로 ###으로 대치되어 나오지만
소수 부분은 오버 플로우가 없이 표시할 공간이 부족한 경우 반올림 되어 나온다.
select last_name, hire_date
from employees
where hire_date = to_date('May 24, 1999', 'fxMonth DD, YYYY');
| LAST_NAME |
HIRE_DATE |
| Grant |
24-MAY-99 |
빈 공간까지 정확하게 체크 (fx 옵션) - 주로 패스워드 체크 할때 사용된다.
RR Format
년도를 4자리로 쓸때는 아무 문제 없지만 YY 입력후 82년을 넣으면 오라클은 2082년으로 인식하고
RR사용시 82라 넣어도 문제가 발생하지 않는다. 하지만 RR은 나중에 문제를 일으킬 요소가 있으므로
YYYY 네자리로 쓰는 것을 권한다.
현재가 2003년 일 때 다음 문장들을 실행하여 결과를 확인하시오.
SQL> SELECT TO_CHAR(TO_DATE('30/01/01','YY/MM/DD'),'YYYY') FROM dual ;
(* 결과가 2030으로 나타난다.)
SQL> SELECT TO_CHAR(TO_DATE('30/01/01','RR/MM/DD'),'YYYY') FROM dual;
(* 결과가 2030으로 나타난다.)
SQL> SELECT TO_CHAR(TO_DATE('80/01/01','YY/MM/DD'),'YYYY') FROM dual;
(* 결과가 2080으로 나타난다.)
SQL> SELECT TO_CHAR(TO_DATE('80/01/01','RR/MM/DD'),'YYYY') FROM dual;
(* 결과가 1980으로 나타난다.)
현재의 시각을 1999년으로 설정한 후 위의 문장들을 실행하여 결과를 확인하시오.
Date Functions
SYSDATE
현재의 오늘 일자를 리턴, Oracle가 설치된 시스템 컴퓨터 날짜를 가진다.
SYSDATE 그 자체가 현재 일자/시간값을 가진다.
SELECT SYSDATE FROM dual;
>> 05/03/13
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD HH24:MI:SS') FROM dual;
>> 2005-03-13 16:26:30
LAST_DAY
나머지 값을 구하는 함수
LAST_DAY(date) date 일자의 해당 마지막 일자를 가리킨다.
SELECT LAST_DAY(SYSDATE) FROM dual;
>> 05/03/31
SELECT TO_CHAR(LAST_DAY(SYSDATE), 'YYYY-MM-DD HH24:MI:SS') FROM dual;
>> 2005/03/31 16:34:40
MONTHS_BETWEEN
두 날짜 사이의 기간을 월 단위로 계산
MONTHS_BETWEEN(data1,data2) data1과 data2 기간을 월 단위를 리턴
date1이 date2보다 클 경우 양수의 결과가 나오는 것을 주의
SELECT MONTHS_BETWEEN('2002/01/13', '2001/05/13') FROM dual;
>> 7
SELECT MONTHS_BETWEEN('2002/01/13', '2002/05/13') FROM dual;
>> -4
SELECT MONTHS_BETWEEN(SYSDATE, '2005/09/13') FROM dual;
>> -6
ADD_MONTHS
해당일 기준으로 해서 이후/이전 날짜로 바꾼다.
ADD_MONTHS(data1,n) data1일을 기준으로 n개월 후를 리턴
SELECT ADD_MONTHS('2002/01/13', 12) FROM dual;
>> 03/01/13
SELECT ADD_MONTHS('2002/01/13', -1) FROM dual;
>> 01/12/13
SELECT ADD_MONTHS(SYSDATE, 12) FROM dual;
>> 06/03/13
NEXT_DAY
해당 일을 기준으로 주어진 요일이 처음 오는 날짜를 리턴
NEXT_DAY(data,요일) date를 기준으로 [요일]에 해당하는 바로 다음
일을 리턴한다. 요일은 아래같이 참조가능하다.
일요일 - 1, 월요일 - 2 .......토요일 - 7
SELECT NEXT_DAY(SYSDATE, '일요일') FROM dual;
>> 05/03/20
SELECT NEXT_DAY('2005/03/15', 7) FROM dual;
>> 05/03/19
출처
http://forceocp.tistory.com/