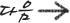2010. 6. 21. 19:02
유전 알고리즘을 이해하기 위한 간단한 프로그램을 짜보자.
시나리오 - { } 중 3개를 골라서 20으로 만드는 문제가 있다고 하자. 여기서 유전체는 각 숫자이며, 유전자는 (1,5,3)와 같이 유전체 3개의 집합으로 이루어진다. 적합도 함수를 20과 얼마나 가까운지를 나타내는 값으로 둔다면, (1,5,3)에 대한 적합도는 f( (1,5,3) ) = 11이 된다.
먼저 첫 세대를 아무렇게나 생성한다. 첫 세대가 만약 { (1,5,3) (8,0,9) (9,9,8) (3,7,5) } 으로 형성되었다고 하자. 각각의 적합도를 구하면, { 11, 3, 7, 5 }이 되며, 이 값이 높을수록 20에서 멀기 때문에 해로서 부적당하다는 것을 의미하며, 따라서 세대를 거침에 따라 살아남을 확률이 낮게 된다.
다음 세대를 형성하기 위해, 이 세대의 개체중 2개의 유전자를 선택한다. 이때 선택은 적합도를 기준으로 확률적선택(룰렛 알고리즘이 자주 쓰인다)이다. 따라서 위의 예에서 (8,0,9)는 (9,9,8)에 비해 훨씬 높은 선택 기회를 가진다. 선택된 2개의 유전자의 유전체는 랜덤한 위치에서 교환되어 새로운 세대가 형성된다. 예로 (8,0,9), (9,9,8) 이 선택되었고 교배위치가 2번째 자리로 무작위로 결정되었다면 다음 세대의 개체는 (8,9,8) ,(9,0,9)로 된다.
출처 - 위키백과
1. 먼저 {1~15} 까지 만들고 여기서 랜덤하게 유전자를 3개를 선택하였다.
2. 유전자 3개중 적합도 함수를 통해 20에 가까운 유전자 2개를 선택하였다. (부모유전자) - 선택연산
3. 선택된 2개의 유전자를 부분 결합하여 새로운 해를 만들어 낸다. - 교차연산
4. 부모유전자중 적합도가 낮은 2개의 유전자를 새롭게 만든 유전자 2개랑 바꿔준다. -대치연산
5. 값들이 20이 되기전에 3개가 모두 같아져 버리는 현상이 있다. 이런 현상이 생길때 변이를 시켜준다. -변이연산

원래대로라면 변이연산을 특정한 확률로 랜덤하게 해줘야 되는 거 같은데
프로그램을 하다보니까 대치연산을 하다보면 어느 순간부터 모든 유전자들이 같게 되는 순간이 있다.
그래서 그 순간에 변이연산을 시켜줘서 20이 나올 때 까지 계속 찾게만들었다.
유전알고리즘에 대해서 아주~~~사아아알~~짝 어떤것인지 알 것 같다.
'프로그래밍 기초 > 자료구조 & 알고리즘' 카테고리의 다른 글
| 유전 알고리즘 (0) | 2010.06.10 |
|---|---|
| 영향력 분포도 (0) | 2010.06.10 |
| 연결리스트를 이용한 이진트리의 순회방법 (0) | 2010.05.14 |
| 트리의 배열표현 방법 (0) | 2010.05.14 |
| 큐 만들기 (0) | 2010.05.14 |