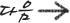- FCFS에서 짧은 프로세스가 피해보는 현상 완화방법
: 시간을 정해놓고 프로세스가 일정 시간 이상을 넘어가는 순간 실행을 강제로 중단시킴
-프로세스 실행시간측정방법
: 클럭(clock) 인터럽트(또는 타이머 인터럽트)
: 클럭인터럽트는 일정간격으로 주기적으로 발생
-시간할당량(time slicing)기법이라고 함
- 시간할당량의 크기(q)가 라운드로빈
:시간할당량이 너무 작다면 문맥교환 오버헤드 증가
:시간할당량이 너무 크다면 FCFS와 비슷해짐
- 시간할당량이 얼마나 되어야 하는가?
:프로세스가 사용자와 최소한 한번 이상 대화하기 충분하거나
:프로세스 내의 어떤 함수 정도는 실행을 마칠 수 있는 충분한 길이
FCFS(선입선출 방식) 연습코드
void Scheduler::Install() //프로세스 생성
{
harddisk.push_back(new Process("A",20,4));
harddisk.push_back(new Process("B",15,5));
harddisk.push_back(new Process("C",18,3));
harddisk.push_back(new Process("D",23,4));
}
void Scheduler::SimulationInit()
{
miter seek = harddisk.begin(); //처음 프로세스 지정
miter end = harddisk.end(); //마지막 프로세스 지정
for( ; seek != end; ++seek)
{
readyqueue.push(*seek); //큐에 프로세스 하나 삽입
(*seek)->IdleToReady(); //삽입한 프로세스를 IdleToReady 로 보냄
}
}
프로세스 클래스
class Process
{
char *pname;
const int tjob; //전체 작업량
const int cjob; //cpu점유시 수행 가능 최대 작업량
int ntjob; //현재 남은 작업량
int ncjob; //현재 cpu점유시 수행 가능 최대 작업량
public:
Process(const char *_pname,int _tjob,int _cjob);
virtual ~Process();
void IdleToReady();
int Running();
void EndProgram();
private:
void InitProcess(const char *_pname);
};
void Process::IdleToReady()
{
ntjob = tjob; //총 작업량을 현재 작업량으로 바꿔놓고 레디상태로!
}
int Process::Running()
{
ncjob = cjob;
while(ntjob!=0 && ncjob!=0) //총 작업량 또는 총 cpu 점유시 총 실행가능시간이 0이되면 프로세스 교체한다
{
eout<<pname;
eout.TimeFlow(4);
ncjob--;
ntjob--;
}
eout<<endl;
return ntjob; //남은 총 작업량을 반환
}
스케쥴 클래스
void Scheduler::Install() //프로세스 생성
{
harddisk.push_back(new Process("A",20,4));
harddisk.push_back(new Process("B",15,5));
harddisk.push_back(new Process("C",18,3));
harddisk.push_back(new Process("D",23,4));
}
void Scheduler::SimulationInit()
{
miter seek = harddisk.begin(); //처음 프로세스 지정
miter end = harddisk.end(); //마지막 프로세스 지정
for( ; seek != end; ++seek)
{
readyqueue.push(*seek); //큐에 프로세스 하나 삽입
(*seek)->IdleToReady(); //삽입한 프로세스를 IdleToReady 로 보냄
}
}
void Scheduler::Simulation()
{
while(!readyqueue.empty()) //큐가 비면 끝낸다
{
Process * temp = readyqueue.front(); //큐에 맨앞에 있는 프로세스를 가르킨다.
readyqueue.pop(); //위에서 가르킨 프로세스를 빼온다.
if(temp->Running()) //운영체제가 빼온 프로세스를 실행시킨다.
{
readyqueue.push(temp); //큐에 프로세스를 다시 삽입한다.
}
}
}
스케줄링 - 큐 대기시간이 적을수록 성능이 좋다!