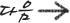//템플릿이란!!?? 함수를 템플릿화하면 자료형은 결정되지않는다! 자료형을 자유롭게!!!
////////////////////////////////////////////////////////////////////////////////////
#include <iostream>
using::std::endl;
using::std::cout;
template <typename T> //템플릿은 모형자!
T Add(T a, T b)
{
return a+b;
}
int main(void)
{
cout<<Add(10,20)<<endl; //한번 모형자로 펜을 잡고(함수를 시작한다) 도형을 그리기 시작하면 펜을 놓기전(함수종료)에는 다른 펜을 사용할수없다
cout<<Add(1.1,2.2)<<endl; //펜을 바꾼다 ( 자료형을 바꾼다 )
return 0;
}
*/
///////////////////////////////////////////////////////////////////////////////////////
//함수 템플릿!!
// "함수 템플릿" 이라고 부른다는 것은 템플릿임을 강조하는 것이다.(함수가 아니라는 뜻이 아니다).
// 함수이기 전에 템플릿의 정의해 해당된다는 것을 의미한다.
template <typename T1, typename T2> //이것은 한 함수에 펜을 2개 사용할수 있게 해준다!
void ShowData(T1 a, T2 b)
{
cout<<a<<endl;
cout<<b<<endl;
}
int main(void)
{
ShowData(1, 2);
ShowData(3, 2.5);
return 0;
}
////////////////////////////////////////////////////////////////////////////////////
//함수 템플릿 특수화 선언
#include <iostream>
using::std::endl;
using::std::cout;
template <typename T> //함수 템플릿 정의
int SizeOf(T a)
{
return sizeof(a);
}
/*
다음과 같이 한 줄에 표현하는 것이 보통이다.
template<> //함수 템플릿 특수화 선언 선언1:template<> int SizeOf(char *a)
선언2:template<> int SizeOf<>(char *a)
int SizeOf(char *a) //전달 인자가 char *인 경우에는 이 함수를 호출 선언3:template<> int SizeOf<char*>(char *a)
{ 선언3의 형태가 가장 정확한 표현이고, 선언1과 2는 선언3을 줄여서 표현한
return strlen(a); 형태이다. 그러므로 선언 3의 표현 방법도 기억하자!!!
}
*/
int main(void)
{
int i=10;
double e=7.7;
char * str= "Good Morning!";
cout<<SizeOf(i)<<endl;
cout<<SizeOf(e)<<endl;
cout<<SizeOf(str)<<endl;
return 0;
}
////////////////////////////////////////////////////////////////////////////////////
template <typename T>
class Data //클래스 템플릿도 선언과 정의를 분리하는 것이 가능하다.
{
T data;
public:
Data(T d);
void SetData(T d);
T GetData();
};
template <typename T>
Data<T>::Data(T d)
{
data = d;
}
template <typename T>
void Data<T>::SetData(T d) // Data<T> 이것은 T타입에 대해서 템플릿으로 정의되어 있는 "Data
{ // 클래스 템플릿"을 의미
// Data::SetData 는 Data클래스의 멤버 함수를 정의하는 것이지
data = d; // "Data 클래스 템플릿"의 멤버 함수를 정의하는 것이 아니다.
}
template <typename T>
T Data<T>::GetData()
{
return data;
}
////////////////////////////////////////////////////////////////////////////////////////
//스택 클래스의 템플릿화!!
template <typename T>
class Stack{
private:
int topidx; // 마지막 입력된 위치의 인덱스
T *stackPtr; // 스택 포인터
public:
Stack(int s=10);
~Stack();
void Push(const T& pushValue);
T Pop();
};
template <typename T>
Stack<T>::Stack(int len)
{
topIdx=-1; // 스택 인덱스 초기화
stackPtr=new T[len];
}
template <typename T>
Stack<T>::~Stack()
{
delete[] stackPtr;
}
template <typename T>
void Stack<T>::Push(const T& pushValue) // 스택에 데이터 입력
{
stackPtr[++topIdx]=pushValue;
}
template <typename T>
T Stack<T>::Pop() //스택에서 꺼냄
{
return stackPtr[topIdx--];
}
int main()
{
Stack<char> stack1(10); // char형 데이터를 저장하기 위한 stack 객체를 생성!
stack1.Push('A');
stack2.Push('B');
stack3.Push('C');
for(int i=0; i<3; i++)
{
cout<<stack1.Pop()<<endl;
}
Stack<int> stack2(10); // int형 데이터 저장을 위한 stack 객체를 생성!
stack2.Push(10);
stack2.Push(20);
stack2.Push(30);
for(int j=0; j<3; j++)
{
cout<<stack2.Pop()<<endl;
}
return 0;
}
// stack 클래스 처럼 템플릿화하면 , 하나의 자료형에 종속되지 않는다!
// 이런식으로 자주 사용되는 자료 구조와 알고림을 템플릿으로 정의해 놓으면, 여러모로 유용할 것이다!
///////////////////////////////////////////////////////////////////////////////////////////////////
//템플릿 함수 or 템플릿 클래스!!!
template <typename T> //함수 템플릿 정의!
T Add(T a, T b)
{
return a+b;
}
int main(void)
{
cout<<Add(10,20)<<endl; // 함수 템플릿의 T가 int로 해석되어서 호출되기를 바라고있다. 그러나 실제로는 컴파일러가 int형 함수를만든다. 그것을 호출한다.
cout<<Add(1.1,2.2)<<endl; // 위와 동일하고 Double형 함수를 만든다!
cout<<Add(10,20)<<endl; // 첫번째줄에서 만든 함수를 호출해온다!
return 0;
// 이처럼 함수 템플릿을 기반으로 해서 만들어지는, 실제 호출이 가능한 함수들을 가리켜 템플릿 함수라고 부른다!
// 또한 템플릿 함수가 생성되는 현상을 가리켜서 "함수 템플릿의 인스턴스화"라고 부른다!
}