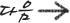2009. 12. 17. 22:20
병합 정렬
1. 분할!! 정렬이 안된 배열을 쪼갠다 [ 7, 5, 12, 18, 4, 9, 11] - 최소원소들이 될때까지 계속 병합정렬 호출
2. 병합!! 최소원소들을 합쳐가면서 병합시킨다.
퀵 정렬과 비교!
퀵 - 역순 , 적당히 정렬에서는 느리고 굉장히 어지러운 정렬에서는 효과를 발휘한다. 일반적으로 빠른 소트로 알려져있다.
컴퓨터상에서는 평균보다 최악의 상황이 더 중요하다.
병합 - 실질적으로 빠른 정렬 , 단점 : 메모리 사용량 ↑
count 정렬
|
1 |
2 |
3 |
4 |
1 |
3 |
1 |
|
1 |
2 |
3 |
4 |
|
3개 |
1개 |
2개 |
1개 |
|
cnt =3 |
cnt =4 |
cnt =6 |
cnt =7 |
분석법을 이용해 표 작성
|
1 |
2 |
3 |
4 |
1 |
3 |
1 |
|
|
|
|
|
|
|
4 |
|
1 |
2 |
3 |
4 |
1 |
3 |
1 |
|
|
|
|
|
|
3 |
4 |
|
1 |
2 |
3 |
4 |
1 |
3 |
1 |
|
|
|
|
|
3 |
3 |
4 |
|
1 |
2 |
3 |
4 |
1 |
3 |
1 |
|
|
|
|
2 |
3 |
3 |
4 |
|
1 |
2 |
3 |
4 |
1 |
3 |
1 |
|
|
|
1 |
2 |
3 |
3 |
4 |
|
1 |
2 |
3 |
4 |
1 |
3 |
1 |
|
|
1 |
1 |
2 |
3 |
3 |
4 |
|
1 |
2 |
3 |
4 |
1 |
3 |
1 |
|
1 |
1 |
1 |
2 |
3 |
3 |
4 |
cnt==0 이 되고 정렬 끝 1 , 1, 1 ,2 ,3 ,3, 4
count
카운트 소트를 이용한 radix sort(기수정렬)
121 121 121 121
753 753 753 275
275 473 473 473
473 275 275 753
첫자리 두번째 세번째
'프로그래밍 기초 > 자료구조 & 알고리즘' 카테고리의 다른 글
| 지뢰찾기 (0) | 2010.05.03 |
|---|---|
| 3n+1 (0) | 2010.05.03 |
| 스케줄링 (라운드 로빈) (0) | 2009.12.17 |
| 연결리스트더미有 (0) | 2009.12.16 |
| 퀵 정렬 (0) | 2009.12.16 |